在预测编码理论框架中,音乐感知是大脑被动接收声学信息与主动生成预期动态结合的过程。基于脑电图(EEG)的音乐识别,是脑机接口、神经解码领域的重要研究方向,其核心目标是从人脑聆听音乐时的脑电信号中,精准识别出对应的音乐内容。传统 EEG 音乐识别模型,大多仅利用与声学特征相关的神经表征,忽略了大脑主动预测过程中产生的期望相关信息,同时传统集成方法依赖随机初始化带来的多样性,存在明显的性能天花板。2026 年 3 月发表于 arXiv 的这项研究,提出了PredANN++ 解码框架,首次系统整合声学与期望相关的两类神经网络表征,将 EEG 音乐识别的准确率提升至 88.7%,为神经解码模型的设计提供了神经科学驱动的全新范式。
传统 EEG 音乐识别方法存在两大核心局限。其一,表征维度单一,仅聚焦于音乐的声学特征对应的神经信号,而大量神经科学研究已证实,大脑听觉皮层会同时编码音乐的声学信息与基于过往旋律生成的预期信息,两类信息具有时空可分离的神经响应,仅用声学表征会丢失大量与音乐感知相关的神经信息。其二,模型集成策略低效,传统深度集成依赖不同随机种子初始化的独立模型,仅能通过初始化差异带来有限的性能增益,无法从根本上提升模型对神经信息的捕捉能力。
针对上述局限,PredANN++ 框架的核心创新,是基于大脑音乐感知的神经机制,构建了三类互补的教师表征,引导 EEG 编码器学习更全面的神经信息。三类表征分别为:声学表征、Surprisal(意外度)表征、Entropy(不确定性)表征,其中后两者共同构成了期望相关的表征体系。研究团队通过音乐自监督模型,直接从原始音频中计算得到两类期望表征,核心公式如下:
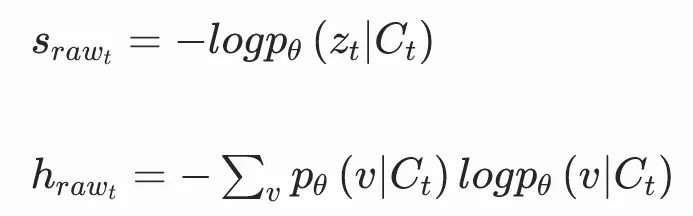
其中,第一个公式定义了 Surprisal,它通过音乐语言模型对下一时刻音频内容的预测概率,量化当前音频事件的意外程度,数值越高,代表该内容越超出听众的预期;第二个公式定义了 Entropy,它量化了模型对未来音频内容的预测不确定性,数值越高,代表对后续音乐走向的不确定程度越强。声学表征则通过自监督音乐模型 MuQ 提取,捕捉音乐的音色、节奏、旋律等基础声学属性。
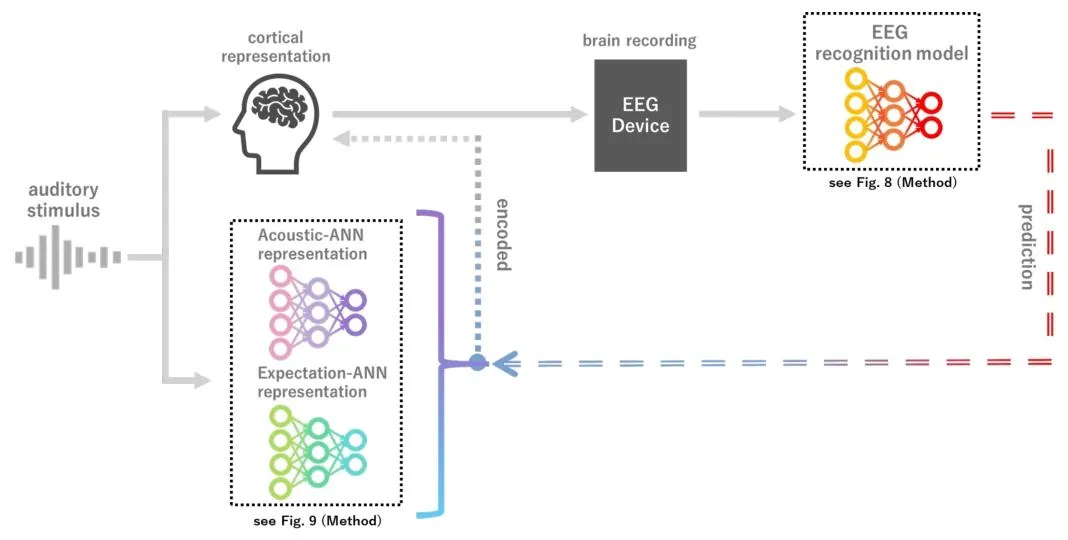
论文Fig.1完整呈现了 PredANN++ 的核心框架:以从音乐中提取的三类表征为教师信号,采用 Transformer 架构的 EEG 编码器为核心,通过 “预训练 - 微调” 两阶段范式完成解码。预训练阶段,模型通过掩码预测任务学习从 EEG 信号中还原三类音乐表征,同时加入歌曲分类辅助损失稳定训练;微调阶段,移除预训练的解码器,仅用 EEG 编码器完成歌曲识别任务。该设计让模型同时捕捉到大脑对音乐的被动声学编码与主动预测过程,大幅提升了神经信息的利用效率。
研究团队基于公开的 NMED-T 数据集完成了系统验证,该数据集包含 20 名受试者聆听 10 首完整音乐时的 128 通道 EEG 记录,识别任务为 10 分类,随机猜测的准确率仅为 10%。
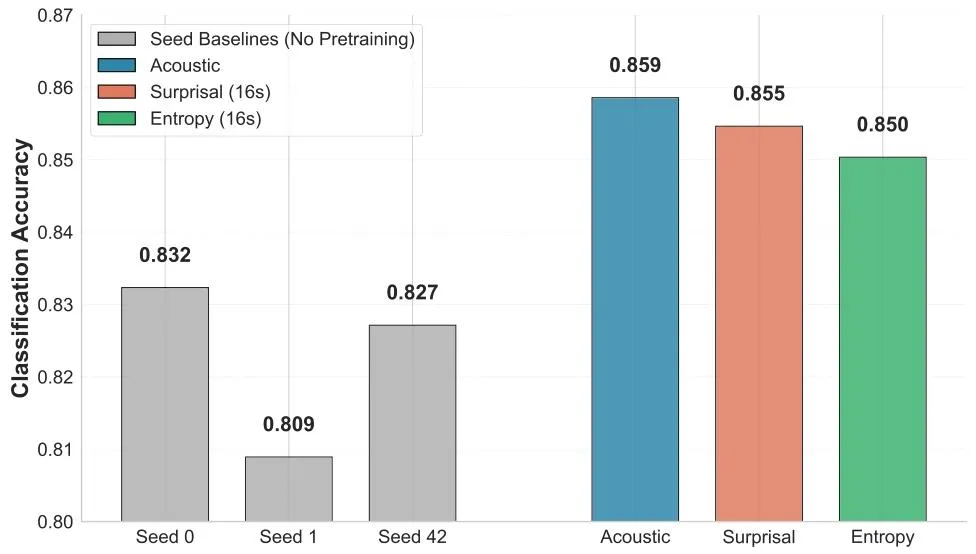
单模型性能测试结果显示(论文Fig.2),三类表征引导的预训练模型,均显著优于无预训练的基线模型。无预训练的基线模型平均准确率为 82.3%,而声学表征模型准确率达 85.9%,Surprisal 表征模型达 85.5%,Entropy 表征模型达 85.0%,三类模型均实现了统计显著的性能提升,证明无论是声学还是期望相关的表征,都能为 EEG 解码提供有效的监督信号。
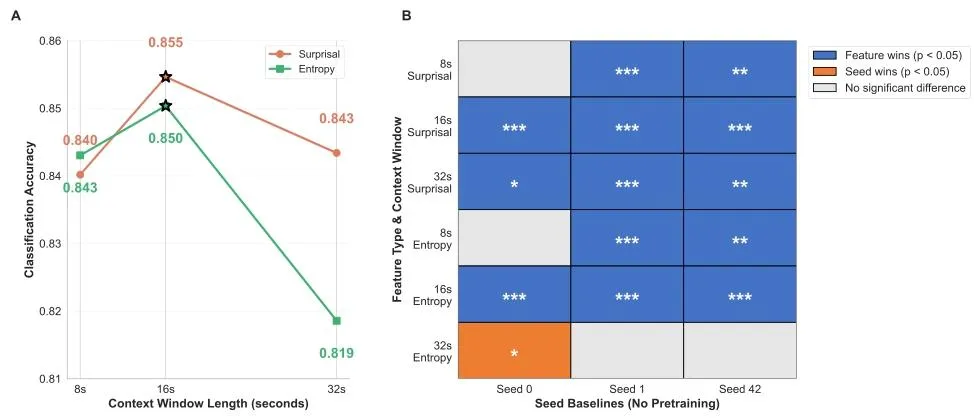
针对期望表征的上下文窗口优化实验显示(论文Fig.4),16 秒的上下文长度为最优配置。在该窗口下,Surprisal 与 Entropy 模型均能稳定超越所有基线模型,而 8 秒窗口过短无法捕捉完整的音乐上下文,32 秒窗口过长则引入了冗余信息,性能均出现下降。这一结果与音乐认知的神经科学研究结论高度契合,证实了该框架捕捉的期望表征,与大脑真实的音乐预测过程具有一致性。
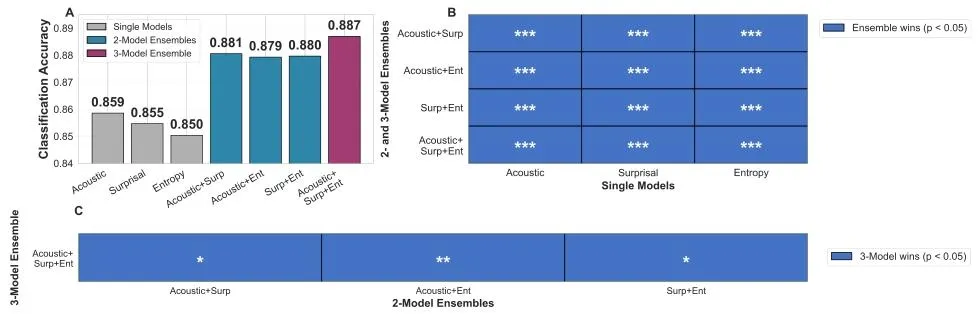
多表征集成实验展现了三类信号的强互补性(论文Fig.5)。通过概率平均的方式集成三类模型,双模型组合的准确率可达 87.9%-88.1%,三模型全集成的准确率进一步提升至 88.7%,较无预训练基线提升 6.4 个百分点,较最优单模型提升 2.8 个百分点。统计检验证实,三模型集成显著优于所有单模型与双模型组合,证明声学、意外度、不确定性三类表征,分别捕捉了大脑音乐感知的不同维度信息,具有极强的互补性。
为进一步验证表征多样性的优势,研究团队将其与传统随机种子集成进行了对比。
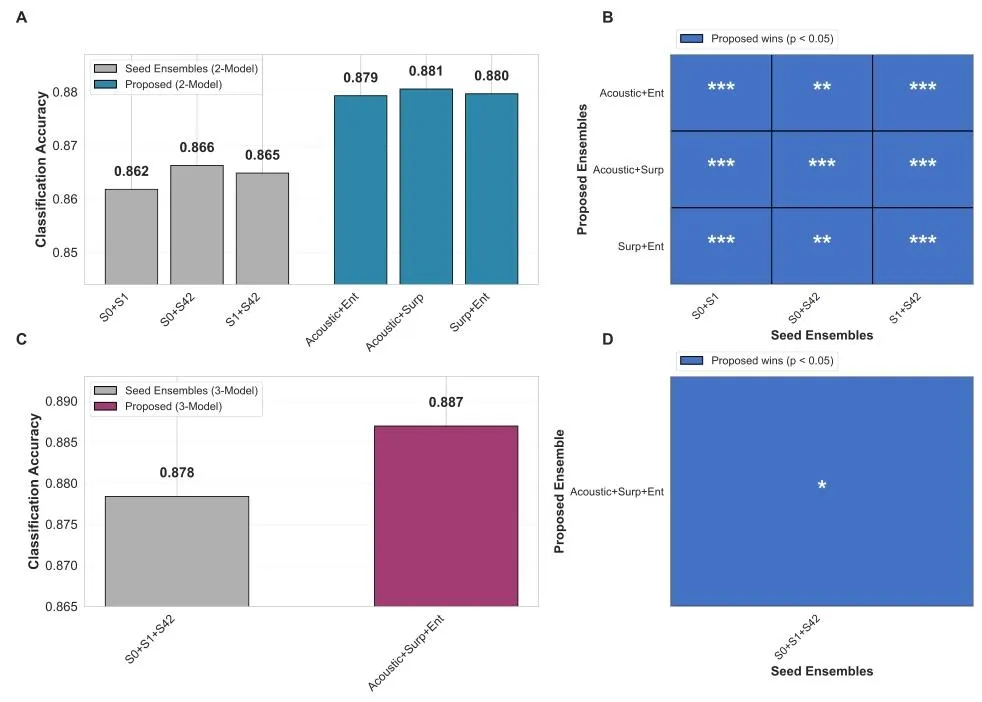
结果显示(论文Fig.7),3 种子集成的最优准确率为 87.8%,而三表征集成以相同的模型数量,实现了 88.7% 的准确率,显著超越了种子集成的性能天花板。同时,所有双表征集成的性能,也均显著优于双种子集成。这一结果证实,基于神经科学机制构建的表征多样性,比单纯依赖随机初始化的集成策略,具有更强的性能提升潜力。
该研究首次系统验证了,期望相关的神经网络表征可作为有效监督信号,提升 EEG 音乐识别的性能。通过整合声学与期望两类互补的神经表征,PredANN++ 框架不仅突破了传统方法的性能瓶颈,更建立了 “神经编码机制指导解码模型设计” 的全新范式。研究提出的期望表征计算方法,无需人工标注与符号化音乐信息,可直接从原始音频中提取,未来可扩展至语音、环境声等更多听觉刺激,为构建通用型 EEG 基础模型提供了可行路径。
论文核心信息
- 论文标题:Expectation and Acoustic Neural Network Representations Enhance Music Identification from Brain Activity
- 发布平台:arXiv 预印本
- 论文链接:https://arxiv.org/abs/2603.03190v2